Phase 1: Production Grade Stock Prediction System design
An end-end, real world ML system that uses LSTM to predict stocks and generate reports.

We’ve all seen the standard “Stock Price Prediction” tutorials. They usually involve a single LSTM model, a CSV file from Yahoo Finance and a plot that looks suspiciously accurate until you realize it’s just lagging the actual price by one day.
But if you want to build something that actually works in a production-like environment, you need more than a model. You need an production grade ML System.
Over the last few weeks, I’ve been building this system. It’s an end-to-end system that handles everything from parent-child transfer learning to agentic news analysis. Here is how it’s put together.
This phase mainly focuses on system design and how to put everything together. Next phase will likely involve K8/cloud deployment.
Note:
This project is an exercise in ML Systems Engineering, not a quest for the perfect financial signal.While I’ve focused on model quality and performance, the primary goal here is to demonstrate a POC for an end to end pipeline. The emphasis is on the engineering decisions, system design the “connective tissue” that makes an ML model functional in a production like environment, rather than simply maximizing prediction accuracy.
Github Repo
Introduction:
If you have ever tried to deploy a machine learning model, you know the “Notebook to Production” gap is more like a canyon. For this project, I set out to bridge that by building a pipeline that manages itself.
The idea is simple: a user asks for a forecast on a ticker, and the system coordinates a small army of services to give an answer that is both mathematically sound and narratively backed.
It’s not trying to beat hedge funds (good luck with that). It’s for learning, experimentation, personal trading ideas or as a starting point for something bigger.
The Stack: More Than Just Python
The core of this system is a distributed architecture designed to handle data ingestion, training and real-time inference.
The Brain (FastAPI): Everything is an asynchronous task. You hit
/train-child, get a task ID, and let the backend do the heavy lifting in the background.The Memory (Redis & Chroma): Compute is expensive. If someone asks for the same analysis twice, Redis pulls the exact cache. If they ask for something similar, Chroma provides a semantic cache of previous LLM insights.
The Context (Ollama & LangGraph): A price chart is blind to news. I built an agent layer that fetches headlines from NewsAPI and Finnhub, then uses an LLM to “read” the sentiment and weigh it against the numerical forecast.

Why the “Parent-Child” Strategy?
Most developers train one model per stock. That is a maintenance nightmare. Instead, I implemented a hierarchical training flow.
I start with a Parent Model. A robust model trained on broad market sector data to capture general “market physics.” When I want to predict a specific ticker like INFY.NS or AAPL, I fine-tune a Child Model on that specific asset. It is faster, more data-efficient and inherits a baseline understanding of how markets move.
But why use an LSTM for this? In a world obsessed with Transformers (I’m too), LSTMs remain a pragmatic choice for time series forecasting for a few reasons:
Memory over Attention: Stocks are sequential. LSTMs are explicitly designed to maintain a hidden state that carries information across time steps, making them naturally suited for the lead lag effects in price action.
Data Efficiency: Transformers are notoriously data hungry. Since we are often dealing with limited high quality daily bars for specific tickers, an LSTM converges much faster and is less prone to overfitting on small datasets.
The Vanishing Gradient Solution: Compared to older RNNs, the LSTM’s gated architecture (Input, Forget and Output gates) allows it to decide which historical events, like a massive earnings beat three months ago, are still relevant to today’s price.
Keeping an Eye on the Regime
The rules of the market change. A model built for a bull market is a liability during a crash. I didn’t want to just hope the model was still accurate, so I built a Monitoring Runner.
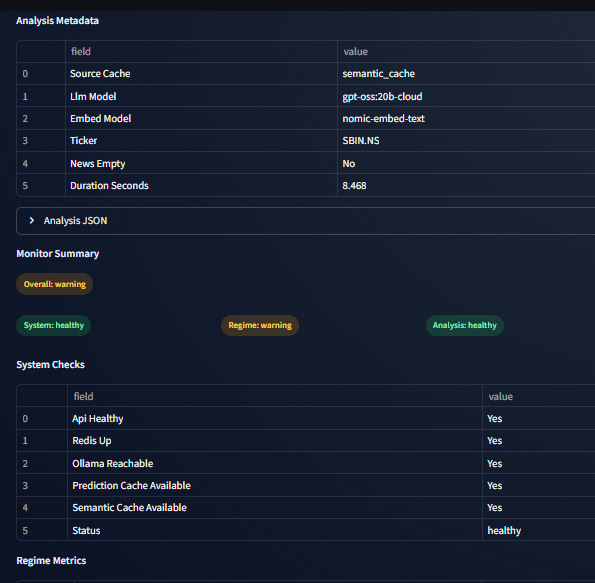
Every time you hit /monitor/{ticker}, the system runs a check for Regime Drift. It compares current market volatility and returns to what the model saw during training. If the market regime has shifted significantly, the system flags it in a JSON artifact. Simply put, it monitors its own relevance.
Observability
If you aren't measuring it, you aren't managing it. The whole pipeline exports metrics to Prometheus, which I visualize in Grafana.
Custom monitoring that checks:
Overall system health
Market regime drift (is the current market behaving differently from training?)
Quality of the generated analysis
All of this runs together with Docker Compose, so spinning up FastAPI, Redis, Prometheus, Grafana, and the Streamlit dashboard is just one command.
Frontend
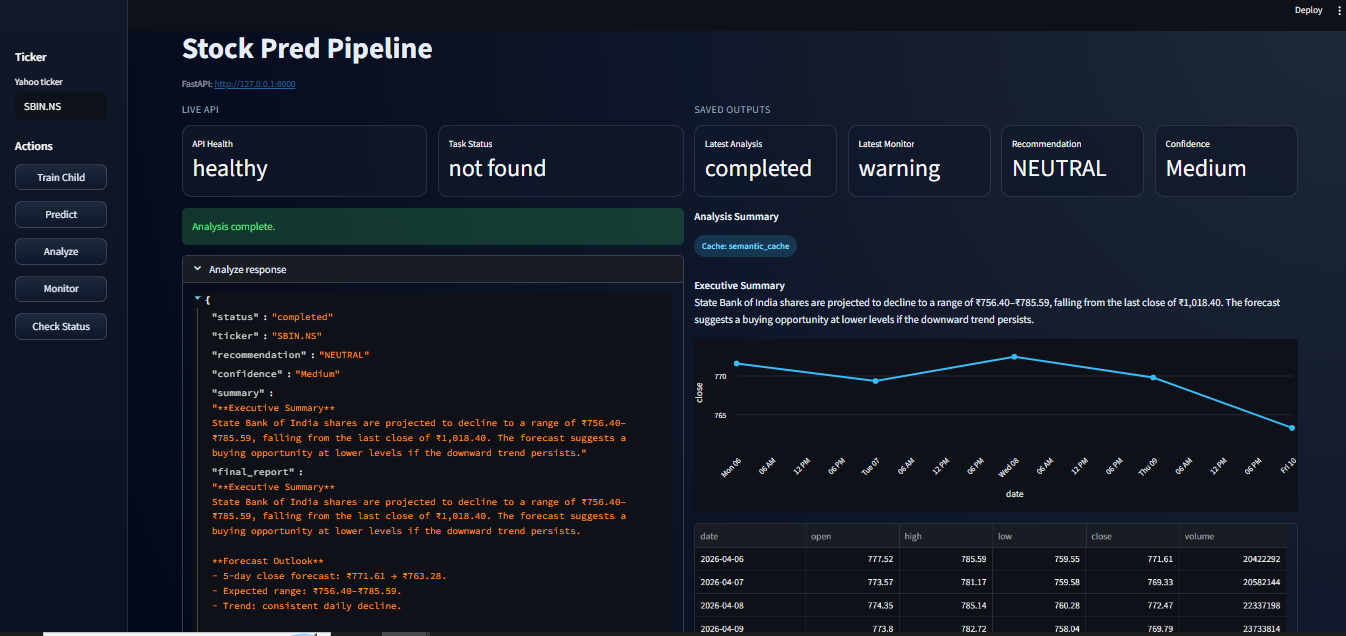
There’s a simple Streamlit app that lets you:
Trigger training, prediction, analysis, or monitoring
View the latest forecast chart
Read the generated analysis
Check monitoring results in cards and tables
What can be done better?
Train a larger LSTM model.
Use Evidently AI for more professional and accurate drift detection.
Deployment to cloud (Next phase, stay tuned!)
Major Learnings:
Every Decision Starts with “It Depends”: There is no perfect architecture, only trade-offs. We chose an LSTM over a Transformer and Redis over a standard DB because those tools fit the specific latency and data constraints of this project.
Solve the Business Problem, Not the Hype: At the end of the day, what matters is the problem you are solving. For this pipeline, the problem wasn’t just predicting a price, it was providing actionable, monitored financial insights.
Stack Alignment: Your current stack must support your ultimate goal. By using FastAPI and Docker, it is a portable, scalable service that actually works in a production like environment.
The Invisible Infrastructure: Trust me, training the ML model will be the easiest part of your job. The real value and often the real difficulty lies in the "connective tissue." The data flow, caching strategy and the observability are what keep the system from flying blind in production.
What’s Next?
We are not done yet. it’s a foundation. The repo is designed so you can swap out the LSTM for a Transformer or change the LLM provider without breaking the plumbing. Next phase will involve deploying this whole thing to cloud, so stay tuned!!
If you found this useful, follow me on GitHub, X and linkedin. You can find the full repo and setup instructions at the link below. Go ahead and fork it, clone it, build it, break it and build it again yourself. Because the truth is, until you’ve built the thing yourself, you don't really understand it.